Opciones de búsqueda en Google imágenes vs Bing
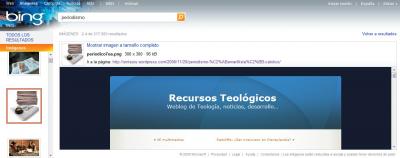
La búsqueda de imágenes de Google ya muestra también opciones avanzadas véase post oficial de Google
De momento estas opciones no están para el español , al igual que las opciones de búsqueda para la búsqueda universal web.
En Google las opciones son:
> Por tamaño: cualquiera, medio, grande, pequeña, mayor que x, exactamente
> Por tipo: cualquiera, cara, foto, viñeta, clip art
> Por color: cualquiera, blanco y negro, selección de color
Si lo comparamos con Bing éste tiene las siguientes opciones:
> Tamaño : cualquiera, pequeña, intermedia, grande, papel tapiz
> Diseño: cualquiera, cuadradas, anchas y altas
> Color: cualquiera, a color, blanco y negro
> Estilo: cualquiera, fotografías, ilustraciones
> Personas: cualquiera, caras, cabeza y hombros, otros
Se puede ver que en el caso de Bing hay más opciones de búsqueda pero en Google hay más posibilidades de filtrado para las opciones de búsqueda. En el caso de Bing dichas opciones están disponibles también para el español
Un aspecto positivo de Bing es que no pierdes la lista de resultados aunque accedas a uno de ellos, ya que tienes un panel lateral donde se pueden visualizar el resto de resultados de imágenes para la búsqueda realizada, lo que ya no se entiende tan bien y creo no está bien resuelto es el enlace superior: "Todos los resultados".
En cambio en Google para ver de nuevo la lista de resultados tienes que hacer clic en "Back to image results"
Por otro lado, en cuanto a medición en Google Analytics, se puede saber el tráfico que te llega de Google imágenes, pero al ser origen de trafico de referencia no es posible conocer las palabras clave por las que llegan tus usuarios a tus imágenes :(
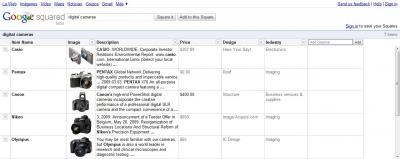
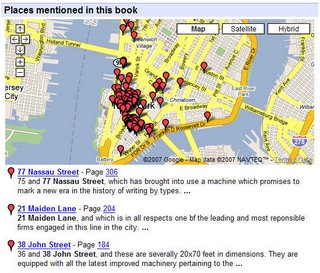

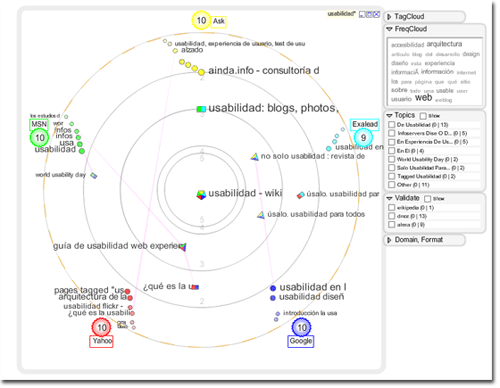


 Algunas de las posibles herramientas, para seguir conociendo mejor el distinto comportamiento de los buscadores y ayudar al usario a seleccionar los que mejor se ajusten a sus necesidades, son:
Algunas de las posibles herramientas, para seguir conociendo mejor el distinto comportamiento de los buscadores y ayudar al usario a seleccionar los que mejor se ajusten a sus necesidades, son: